Implement near real-time eventing from Snowflake to RDS - part 1
This two-part series will explore an exciting data integration architecture and apply various skills and diverse knowledge to deliver a robust solution.


Part 1: Understanding the Architecture and Key Concepts in Data Integration
This two-part series will explore an exciting data integration architecture and apply various skills and diverse knowledge to deliver a robust solution. In the first part, we focus on understanding the developed architecture and its unique aspects. The second part will provide a comprehensive breakdown of resources, goals, and considerations involved in its implementation.
The Current Architecture: Snowflake as a Source
Typically, Snowflake is used as a destination in data pipelines due to its strengths as a data warehouse for analytics. However, in this architecture, Snowflake is not the sink but the source. This deviation from the norm exposes the flexibility of modern data integration pipelines.
Objective: Move data changes from Snowflake to an AWS RDS Aurora cluster via Kafka with the following components:
- Snowflake Streams: Captures data changes efficiently.
- Kafka: Processes events and sinks the data into the data store.
- AWS RDS Aurora: The final destination for data storage.
- Avro Format with Schema Registry: Ensures structured, schema-validated data transfer.
Below is a diagram illustrating this architecture:
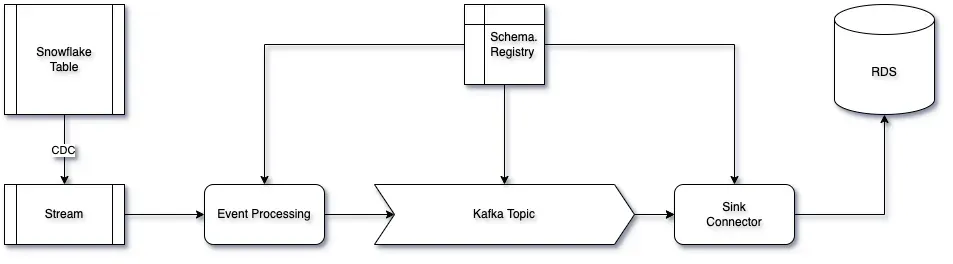
Key Architecture Goals
The primary objective is to move data from Snowflake to AWS RDS Aurora with the following considerations:
- Streamlined Data Transfer: Utilize Snowflake Streams to capture changes, removing the need for a connector and bypassing traditional ETL pulling.
- Event-Driven Processing: Kafka ensures that each event (message) is processed in near real-time.
- Validation and Structuring: Use the Avro format (Schema Registry) to verify message structures before delivery.
Typical Architecture vs. Current Architecture
In a typical data pipeline:
- Data sources feed into Kafka using native or connectors.
- Kafka acts as an intermediary, processing and pushing data to Snowflake as the destination.
- RDS or other operational databases often act as upstream sources of the transactions.
Key Differences in the Current Architecture:
- Snowflake acts as the source, not the sink.
- AWS RDS Aurora becomes the final sink.
- The pushing model eliminates the need for traditional batch pulls, enabling near real-time processing.
Pushing vs. Pulling Models
- Pulling Model:
- The connectors query the source at intervals to retrieve changes, introducing a mechanism of uniqueness identity and/or timestamp.
- Pros:
- Simple setup for legacy systems.
- Controlled data flow based on pull frequency.
- Cons:
- Higher latency due to periodic batch pulls.
- Increased workload on the source system during pulls.
- Lost granularity of data changes (squash all changes between pulls in a single event)
- Risk of missing incremental changes if not carefully managed.
- Pushing Model:
- The source actively sends changes to downstream systems as they occur as events (messages).
- Pros:
- Near real-time updates.
- Reduced source system workload as changes are streamed, not queried.
- Ensures no loss of incremental changes.
- Cons:
- Requires robust error handling and retry mechanisms.
- Potentially more complex initial setup.
Conclusion of Part 1
This architecture offers an innovative way to manage near real-time data integration by leveraging Snowflake Streams, Kafka, and AWS RDS Aurora. Choosing a pushing model over pulling enables real-time processing and efficiency but requires careful orchestration of multiple technologies.
In Part 2, we will:
- Deep dive into each pipeline component and its role.
- Loot into the advantages and challenges of using Avro and Schema Registry.
- Provide implementation challenges.
Stay tuned for the under-the-hood explanation of how these components fit into a technological stack and perform together to deliver a modern, scalable data pipeline.