Where Data at Rest Meets Data in Motion
Explore how historical data (at rest) and real-time updates (data in motion) merge in a modern pipeline. Technologies like Kafka, ByteWax, Flink and Faust process data seamlessly, transforming raw JSON into actionable insights on real-time dashboards.

Unified Data Architecture
The future of enterprise data strategy belongs to organizations that can seamlessly combine data at rest and data in motion, bridging the gap between historical insights and real-time decision-making. For leaders in data, technology, and business, understanding these two foundational paradigms is crucial when building architectures that empower agility, innovation, and growth.
Two Core Paradigms of Modern Data Architectures
To understand modern data architectures, it’s important to grasp two fundamental concepts: data at rest and data in motion. These paradigms describe how data is processed, stored, and utilized in systems.
Data at Rest: Insights from Historical Context
- What it is: Refers to stored records, data housed in traditional data warehouses, lakes, or other storage solutions.
- Why it matters:
- Powers batch processing, historical analytics, and trend analysis, uncovering critical patterns to guide long-term business decisions.
- Fuels advances like machine learning models, ensuring that insights are grounded in large sets of robust historical data.
- CDO’s Perspective: Data at rest forms the foundation of enterprise-wide data governance and compliance while enabling scalable analytics.
- Example: Historical sales and inventory trends stored in enterprise data warehouses to analyze customer buying behaviors and optimize future inventory levels.
Data in Motion: Agility from Real-Time Context
- What it is: Refers to the flow of real-time streams, representing live interactions like transactions, IoT sensor feeds, or operational updates.
- Why it matters:
- Enables continuous processing for immediate action, such as triggering alerts for low inventory or powering real-time dashboards.
- Provides businesses with the flexibility to respond to market demands instantly, ensuring customer-centric operations.
- CTO’s Perspective: Data in motion embodies technological agility, ensuring systems are both high-performing and scalable for real-time demands.
- Example: Live updates from IoT devices tracking inventory levels, syncing real-time availability with both customer-facing dashboards and backend systems.
The CEO’s Vision: Data Meets Business Value
When unified, data at rest and data in motion serve as the foundation for a data-driven enterprise, one that predicts trends from historical data while responding dynamically to real-time signals. This holistic approach allows businesses to:
- Deliver exceptional customer experiences with real-time information (e.g., accurate delivery times, stock availability).
- Drive operational efficiency through predictive analytics informed by both past and present data.
- Maximize ROI on technology investments by balancing long-term insights with short-term agility.
In a world increasingly defined by speed and data, organizations that successfully synchronize these two paradigms will realize competitive advantages, empowering leaders to make informed decisions while staying ahead of disruption.
Unified Vision: Principles of Convergence
Unifying data at rest and data in motion empowers organizations to:
- Process live streams alongside historical datasets.
- Derive real-time insights enriched by historical learnings.
- Build systems that are agile, scalable, and resilient.
To showcase how this works, we use a dynamic pricing pipeline example. This pipeline demonstrates:
- Flattening JSON-based inventory records (data in motion).
- Applying historical pricing rules (data at rest).
- Publishing pricing updates dynamically for real-time dashboards.
Detailed Processing Workflow
Original JSON Object: Input
We start with a product schema describing inventory at multiple warehouses:
{
"product_id": "12345",
"name": "Product A",
"inventory": [
{
"warehouse_id": "WH1",
"quantity": 100,
"delivery_time": 3,
"restocking_time": 7
},
{
"warehouse_id": "WH2",
"quantity": 50,
"delivery_time": 5,
"restocking_time": 10
}
],
"physical_characteristics": {
"weight": 10,
"length": 20,
"width": 15,
"height": 10
}
}
This data flows into the pipeline as events (data in motion), representing live inventory updates for each product.
Flattening Inventory: Per-Warehouse Records
Since each inventory list contains multiple warehouse details, we use a flattening function to transform the JSON input into individual records (one per warehouse). This is crucial for real-time dashboards as flattened records are easier to monitor.
Python Implementation: Flatten Inventory
def flatten_inventory(msg: dict):
"""Splits warehouse-specific details into individual records."""
inventory = msg.get("inventory", [])
if not isinstance(inventory, list):
return
for inv in inventory:
yield {
"product_id": msg.get("product_id"),
"warehouse_id": inv.get("warehouse_id"),
"quantity": inv.get("quantity", 0)
}
Flattened Output (Example Records):
After this step, our processed data looks like this:
{
"product_id": "12345",
"warehouse_id": "WH1",
"quantity": 100
}
{
"product_id": "12345",
"warehouse_id": "WH2",
"quantity": 50
}
Dynamic Pricing Pipeline Implementation
After flattening the inventory, we apply tier-based pricing rules (a representation of data at rest) enriched by inventory levels (from data in motion). We then publish the dynamic prices to real-time dashboards.
Example 1: Bytewax Implementation
Bytewax is a Python-native stream processor that integrates seamlessly with Kafka, allowing real-time event handling and transformations.
Example: Data Processing from Kafka to Iceberg
This example highlights how Bytewax can be used to process data directly from Kafka and write it into an Iceberg table for unified storage.
from bytewax.dataflow import Dataflow
from bytewax.connectors.kafka import KafkaSource
from pyiceberg.catalog import load_catalog
import json
import uuid
# -------------------------
# Load Iceberg catalog
# -------------------------
catalog = load_catalog(
"default",
**{
"type": "rest",
"uri": "http://localhost:8181"
}
)
table = catalog.load_table("pricing.events")
# -------------------------
# Business logic
# -------------------------
def price_for_quantity(qty):
if qty < 10:
return 10.0
elif qty < 50:
return 9.0
return 8.0
def process_event(event_str):
"""Parse, flatten, enrich"""
try:
product = json.loads(event_str)
results = []
for inv in product.get("inventory", []):
qty = inv["quantity"]
results.append({
"product_id": product["product_id"],
"warehouse_id": inv["warehouse_id"],
"quantity": qty,
"price": price_for_quantity(qty)
})
return results
except Exception:
return []
# -------------------------
# Iceberg Writer
# -------------------------
class IcebergSink:
def __init__(self, table):
self.table = table
self.buffer = []
def write(self, item):
if item:
self.buffer.append(item)
# flush in batches
if len(self.buffer) >= 100:
self.flush()
def flush(self):
if not self.buffer:
return
with self.table.new_append() as append:
for record in self.buffer:
append.append(record)
self.buffer.clear()
sink = IcebergSink(table)
# -------------------------
# Bytewax Flow
# -------------------------
flow = Dataflow("kafka_to_iceberg")
flow.input(
"input",
KafkaSource(
brokers=["localhost:9092"],
topics=["products"]
)
)
flow.flat_map(process_event)
flow.map(lambda x: sink.write(x))Key Points:
- Data Source: Reads from a Kafka topic in Avro format.
- Processing: Includes mapping and filtering functionality, removing records where
age <= 30. - Output to Iceberg: Writes processed data into an Iceberg table for further usage (batch or streaming queries).
Bytewax Code Pipeline:
from bytewax.dataflow import Dataflow
from bytewax.connectors.kafka import KafkaOutput
# Step 1: Create a stream processing flow
flow = Dataflow()
# Step 2: Flatten inventory records for real-time monitoring
flow.flat_map(flatten_inventory) \
# Step 3: Calculate dynamic prices using tier rules
.map(lambda inv: {
**inv,
"price": price_for_quantity(inv["quantity"]) # Tier-based pricing
}) \
# Step 4: Publish to Kafka for live dashboards
.output("kafka", KafkaOutput(topic="price_list", value_format="json", key_fields=["product_id", "warehouse_id"]))
# Pricing function (Amount derived from inventory levels)
def price_for_quantity(qty: int) -> float:
if qty < 10:
return 10.0
elif qty < 50:
return 9.0
return 8.0 # Bulk pricing
Bytewax Advantages:
- Pythonic Design: Suited for Python developers.
- Streaming Simplicity: Effortless Kafka integration for real-time data flows.
- Real-Time Dashboards: Feed flattened and enriched records directly into visualization tools.
Example 2: Faust Implementation
Faust is a distributed framework for building event-driven applications that process live data streams, ideal for Kafka-based systems.
A Faust app can handle real-time event streams from Kafka, process the data (apply filters/mapping logic), and write it directly into an Iceberg table.
import faust
import json
from pyiceberg.catalog import load_catalog
# -------------------------
# Faust App
# -------------------------
app = faust.App(
"pricing_pipeline",
broker="kafka://localhost:9092"
)
# -------------------------
# Schema
# -------------------------
class Event(faust.Record):
name: str
age: int
input_topic = app.topic("my_topic", value_type=Event)
# -------------------------
# Iceberg Setup
# -------------------------
catalog = load_catalog(
"default",
**{
"type": "rest",
"uri": "http://localhost:8181"
}
)
table = catalog.load_table("default.events")
# -------------------------
# Buffer for batch writes
# -------------------------
buffer = []
BATCH_SIZE = 100
def flush():
global buffer
if not buffer:
return
with table.new_append() as append:
for record in buffer:
append.append(record)
buffer.clear()
# -------------------------
# Stream Processing
# -------------------------
@app.agent(input_topic)
async def process(events):
async for event in events:
if event.age > 30:
record = {
"name": event.name,
"age": event.age
}
buffer.append(record)
if len(buffer) >= BATCH_SIZE:
flush()
# Optional: flush on shutdown
@app.timer(interval=10.0)
async def periodic_flush():
flush()
# -------------------------
# Run
# -------------------------
if __name__ == "__main__":
app.main()
Key Points:
- Agent Processing: An agent processes real-time streams, filtering events by the
agefield. - Sink to Iceberg: Events passing the filter are written directly into an Iceberg table for batch-stream capabilities.
- Scalability: Faust handles distributed event processing, making it suitable for larger-scale implementations.
Faust Code Pipeline:
import faust
app = faust.App("pricing-pipeline", broker="kafka://localhost:9092")
# -------------------------
# Schema
# -------------------------
class InventoryItem(faust.Record):
warehouse_id: str
quantity: int
class Product(faust.Record):
product_id: str
inventory: list[InventoryItem]
# -------------------------
# Topics
# -------------------------
input_topic = app.topic("products", value_type=Product)
price_list_topic = app.topic("price_list", value_type=dict)
# -------------------------
# Business logic
# -------------------------
def price_for_quantity(qty: int) -> float:
if qty < 10:
return 10.0
elif qty < 50:
return 9.0
return 8.0
# -------------------------
# Processing
# -------------------------
@app.agent(input_topic)
async def process_inventory(products):
"""Processes incoming inventory for pricing updates."""
async for product in products:
if not product.inventory:
continue
for inv in product.inventory:
try:
price = price_for_quantity(inv.quantity)
await price_list_topic.send(
key=f"{product.product_id}|{inv.warehouse_id}",
value={
"product_id": product.product_id,
"warehouse_id": inv.warehouse_id,
"quantity": inv.quantity,
"price": price
}
)
except Exception as e:
# In real systems: log or send to dead-letter topic
print(f"Error processing record: {e}")Example 3: Flink Implementation
Apache Flink is a distributed stream processing framework ideal for real-time data enrichment and transformation.
Flink Code Pipeline:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors.kafka import FlinkKafkaConsumer, FlinkKafkaProducer
from pyflink.common.serialization import SimpleStringSchema
import json
# -------------------------
# Environment
# -------------------------
env = StreamExecutionEnvironment.get_execution_environment()
# -------------------------
# Kafka Source (Inventory Stream)
# -------------------------
consumer = FlinkKafkaConsumer(
topics="inventory_updates",
deserialization_schema=SimpleStringSchema(),
properties={
"bootstrap.servers": "localhost:9092",
"group.id": "inventory"
}
)
# -------------------------
# Kafka Sink
# -------------------------
producer = FlinkKafkaProducer(
topic="price_list",
serialization_schema=SimpleStringSchema(),
producer_config={
"bootstrap.servers": "localhost:9092"
}
)
# -------------------------
# Simulated pricing lookup (data at rest)
# -------------------------
PRICING_RULES = {
"premium": 15.0,
"standard": 10.0,
"basic": 5.0
}
def get_price_tier(product_id):
# Simulate lookup (in reality: DB, state, or broadcast stream)
return "standard"
def calculate_price(quantity, tier):
base_price = PRICING_RULES.get(tier, 5.0)
if quantity < 10:
return base_price * 1.2
elif quantity < 50:
return base_price
return base_price * 0.8
# -------------------------
# Processing Function
# -------------------------
def process_event(event_str):
try:
product = json.loads(event_str)
results = []
for inv in product.get("inventory", []):
qty = inv["quantity"]
tier = get_price_tier(product["product_id"])
results.append(json.dumps({
"product_id": product["product_id"],
"warehouse_id": inv["warehouse_id"],
"quantity": qty,
"price_tier": tier,
"price": calculate_price(qty, tier)
}))
return results
except Exception:
return []
# -------------------------
# Pipeline
# -------------------------
stream = env.add_source(consumer)
processed = stream.flat_map(process_event)
processed.add_sink(producer)
# -------------------------
# Execute
# -------------------------
env.execute("flink_pricing_pipeline")Key Points:
- Data Source: Flink consumes real-time inventory data and historical pricing data from Kafka topics.
- Processing: The inventory data is enriched with pricing tiers and adjusted prices based on predefined logic.
- Output to Kafka: Enriched data is published to the
price_listKafka topic, feeding real-time dashboards.
Flink Advantages:
- Scalable Processing: Handles high-throughput, distributed data streams.
- Flexible Enrichment: Joins real-time and historical data for dynamic insights.
- Real-Time Dashboards: Outputs directly into Kafka for immediate visualization.
Unified Workflow Benefits
- Data in Motion Integration: Real-time inventory updates from Kafka (
productstopic). - Transformation and Flattening: Stream processing flattens nested JSON and applies logic.
- Data at Rest Influence: Pricing rules originate from static batch layers (historical tiers).
- Real-Time Feeds: Published pricing updates (
price_listtopic), ready for dashboards.
High-Level Architecture for the Solution:
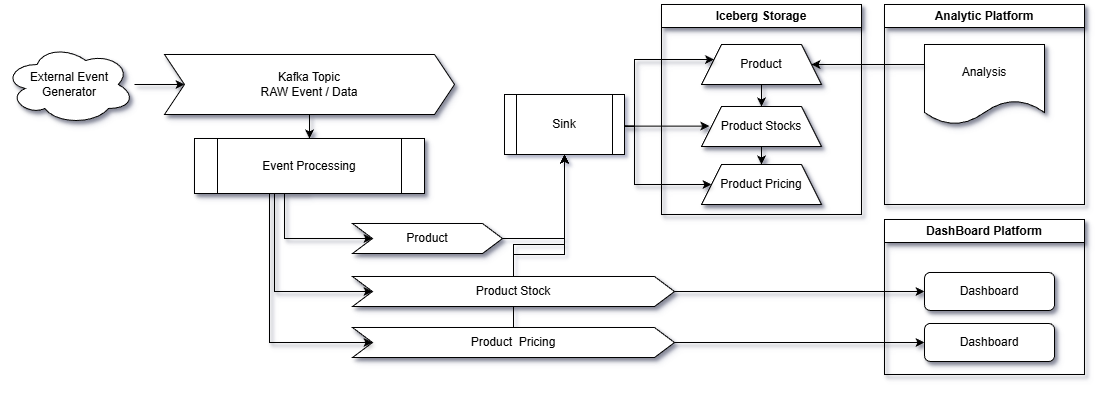
The architecture for this solution revolves around a real-time event-driven pipeline, leveraging Apache Kafka as the backbone for data streaming and messaging. Data from external sources like SAP Asapio is ingested into a raw Kafka topic (inventory_raw) where it's first processed by Event Processor 1 to flatten and enrich the inventory data. The enriched data is distributed to multiple Kafka topics, serving distinct use cases: (1) real-time dashboards, (2) long-term storage and analytics on Iceberg, and (3) alerts or downstream applications. At its core, this architecture ensures parallel processing for performance, decoupled systems for scalability, and unified access to both real-time streams and historical data. Visualization tools like Grafana, Tableau, or custom frontends consume the dashboard_metrics Kafka topic for dynamic updates, providing users with actionable insights in real time. The entire pipeline supports both batch and stream processing, ensuring efficiency and versatility for diverse inventory management tasks.
Next Steps for Scalability
This pipeline is just the beginning. Potential enhancements include:
- Regional Multipliers:
- Adjust prices per warehouse based on regional factors (e.g., taxes).
- Promotions:
- Add conditional discounts during holidays or for loyal customers.
- Advanced Queries:
- Enhance real-time dashboards by integrating Iceberg tables for live querying.
- Machine Learning:
- Predict demand and optimize pricing dynamically based on live interactions.
Final Thoughts: Showcasing Data Paradigms
The pricing pipeline example serves as a stellar demonstration of the power of combining data at rest and data in motion, showcasing how these two paradigms together enable seamless, real-time insights and decision-making:
- Data at Rest Meets Data in Motion:
Historical pricing tiers (data at rest) integrate with real-time inventory updates (data in motion) to form a unified, dynamic view of pricing strategy. This collaboration ensures that decisions are as grounded in historical trends as they are in the current market reality. - Architectural Excellence:
Modern technologies like Apache Kafka, Apache Flink, Bytewax, and Faust are the building blocks of this architecture, illustrating how a robust, scalable pipeline supports real-time data processing, enrichment, and streaming. - From Raw to Real-Time:
The seamless flow of data, from raw JSON ingestion to polished, actionable insights displayed on real-time dashboards, represents the end-to-end efficiency of this unified data architecture. It highlights how businesses can use the synergy of these paradigms to drive both operational efficiency and strategic decision-making.
By leveraging these capabilities, organizations can unlock the full potential of their data, ensuring they remain competitive and responsive in an increasingly dynamic business landscape.